
CrowdStrike Global IT Outage: Time to Reflect on the Process for Security Vendor Updates?
The CrowdStrike-Microsoft outage shines a light on striking a delicate balance between velocity, hygiene, and change management when it comes to rolling out software updates and patches.
Over the past 24 hours, “the largest IT outage in history” disrupted businesses across the globe. Resulting from an issue with a CrowdStrike Falcon content update for Windows Hosts, the outage serves as a stark reminder of our dependency on technology – and the impact of downtime. Availability is a security issue.
On behalf of NetSPI, we’re sending moral support to everyone impacted and those at CrowdStrike getting the world back on track. Outages as the result of constant security updates are inevitable. Companies need to push updates quickly to stay ahead of threat actors. When they do, quality assurance might lag and create availability outages such as this. It’s the push and pull of velocity, hygiene, and change management.
Contrary to the public’s perception, while the issue stems from a cybersecurity vendor, the outage was not caused by a cybersecurity incident or breach. Given the cybersecurity team owns the technology involved that introduced the issue, there are plenty of lessons for our industry to learn from this event.
What we know – so far
What happened?
CrowdStrike issued a routine content update to its Falcon software. A bug in the update caused the software to fail to boot, resulting in customers getting the “Blue Screen of Death,” with no access to their systems. The issue only impacts Windows hosts.
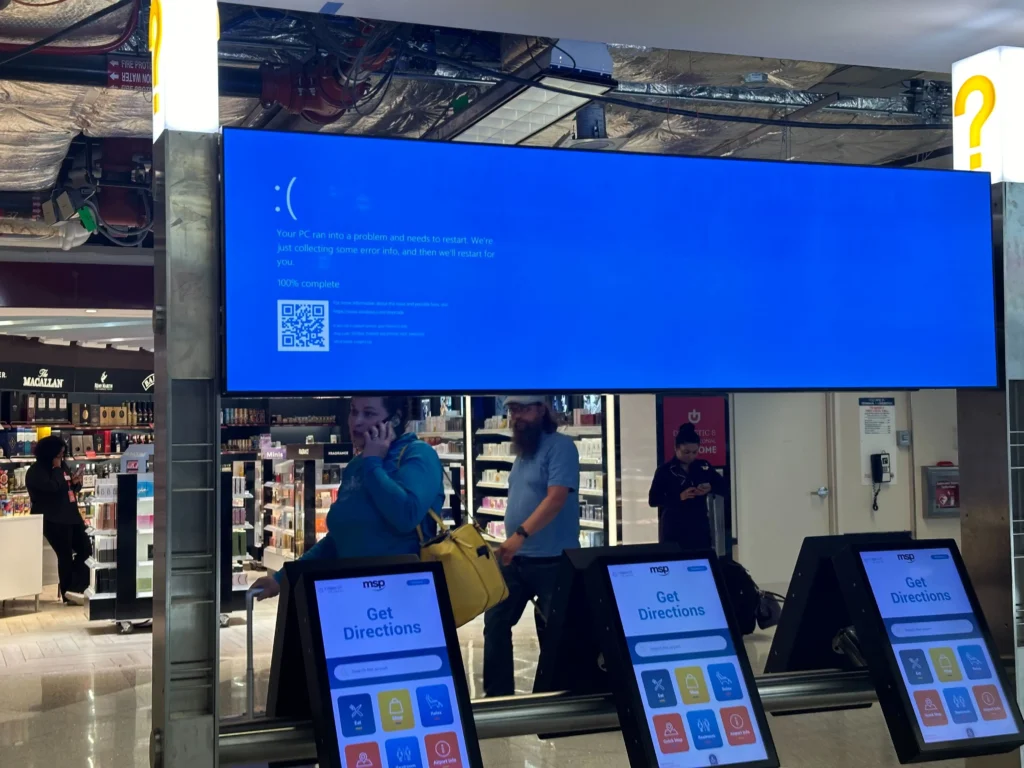
Screens at Minneapolis-St. Paul International Airport on July 19
Who is impacted?
Any company that uses CrowdStrike Falcon hosted on a Windows operating system. Some of the most prominent organizations use CrowdStrike, from emergency services to financial institutions to airports. The impact is global and not isolated to one geography or industry.
What is the fix?
At the time of writing this, an update has been deployed. According to CrowdStrike, it has “identified a content deployment related to this issue and reverted those changes.” However, if you are unable to stay online to receive the changes, the following manual steps can be taken:
- Boot Windows into Safe Mode or the Windows Recovery Environment
- Navigate to the C:\Windows\System32\drivers\CrowdStrike directory
- Locate the file matching “C-00000291*.sys”, and delete it
- Boot the host normally (BitLocker-encrypted hosts may require a recovery key)
CrowdStrike’s website is the best place to receive real-time updates and steps for recovery. Please visit https://www.crowdstrike.com/blog/statement-on-falcon-content-update-for-windows-hosts/ to learn more.
Cybersecurity lessons to learn – do not let this distract from the bigger picture
Over the past decade, we have made incredible progress in the velocity at which we deploy security technology (such as CrowdStrike) and apply critical patches to our enterprises. This has taken substantial risk off the table for the global economy and in relative terms, has come with very little consequence to the reliability or availability of our systems.
Anyone that has ever been in a security organization will know well of the ongoing challenge between security and IT, to push the envelope on patching faster and be as agile as possible when it comes to deploying new controls in the face of an ever-evolving threat. Concerns that security tools “take up too much bandwidth” or “consume too much CPU” have largely been overcome, with the realization of the huge benefits they provide.
The events of the last 24 hours will, without question, be used in many organizations to rethink this position. IT teams will be faced with critical questions around vendor updates. Do we need more process around security vendor updates? Are we patching too quickly and ignoring historical QA best practices?


IT teams will be faced with critical questions around vendor updates. Do we need more process around security vendor updates? Are we patching too quickly and ignoring historical QA best practices?
While there is still much to be known about the events surrounding the CrowdStrike update, what we do know is that this appears to be a first and rare occurrence. Products like CrowdStrike and our own solutions at NetSPI prevent disruptions to systems that power the global economy on a daily basis.
This outage shines a light on striking a delicate balance between velocity, hygiene, and change management when it comes to rolling out software updates and patches. The C-Suite and Boards should exercise restraint in knee-jerk reactions, potentially unwinding the substantial progress we have made as an industry in improving patching response times and speed of implementing security products.
Yes, CrowdStrike owes its customers and impacted parties an explanation as to what happened and what measures they are implementing to prevent this in the future. But we still have a very long way to go in getting our businesses to have the agility they need to achieve a state of cyber resilience, and this should not distract companies from the bigger picture.
In talking with Sam Kirkman, NetSPI Director of EMEA Services, he shared a similar sentiment. “This incident highlights dependency that many organizations have on key pieces of software. While that risk is well understood, it is often accepted due to the greater risk of leaving digital unprotected from cyberattacks.”
He also offered a more technical take, “any organization publishing code directly onto its customers systems holds a great deal of responsibility. That responsibility is even greater when that code is run with unrestricted privileges, in ‘kernel mode’.”
Sam recommends, “extensive testing on real-world devices should be mandatory for every change to code that is this critical. It will take time to determine how this situation could occur despite the mechanisms CrowdStrike has in place to prevent it.”
“It is important to note that mistakes can – and will – happen anywhere,” Sam reiterated. “It is extremely unlikely that this situation could arise from a mistake made by one person. It is more likely that a chain of events has led to this situation, and it is possible that factors beyond the control of CrowdStrike may have led to this result. At this stage, the priority is to restore operations for all affected organizations, after which a comprehensive investigation of the root causes should take place.”
Getting back on track
Both CrowdStrike and Microsoft have been quick to address the issue, with CrowdStrike CEO George Kurtz and Microsoft CEO Satya Nadella leading their teams in damage control and mitigation efforts. Their assurance that this was not a cyberattack offers little solace to those affected but highlights a vital aspect of today’s threat landscape: not all disruptions come from malicious actors.
As we navigate the aftermath of the Microsoft-CrowdStrike outage, it’s essential to reflect on the lessons learned. This event is not just a technical failure but a call to action for the IT industry to reevaluate and reinforce our digital infrastructure. By fostering a culture of transparency, accountability, and continuous improvement, we can not only address the immediate challenges but also build a more resilient future.
Authors:

Explore more blog posts
CTEM Defined: The Fundamentals of Continuous Threat Exposure Management
Learn how continuous threat exposure management (CTEM) boosts cybersecurity with proactive strategies to assess, manage, and reduce risks.

Balancing Security and Usability of Large Language Models: An LLM Benchmarking Framework
Explore the integration of Large Language Models (LLMs) in critical systems and the balance between security and usability with a new LLM benchmarking framework.

From Informational to Critical: Chaining & Elevating Web Vulnerabilities
Learn about administrative access and Remote Code Execution (RCE) exploitation from a recent Web Application Pentest.